Skip to main content
Search
Search This Blog
Thompson's Technological Insight
Posts
Showing posts from August, 2016
Show all
August 23, 2016
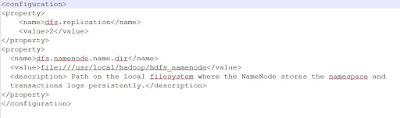
Hadoop - How to setup a Hadoop Cluster
August 09, 2016
JAVA - _JAVA_OPTIONS and JAVA_TOOL_OPTIONS environment variable
August 09, 2016
JAVA - _JAVA_OPTIONS and JAVA_TOOL_OPTIONS environment variable
Newer Posts
Older Posts
Home